
微信公众号也提及了
在 AI 产业链进入智能体时代之后,企业真正关心的问题已经不只是“有没有大模型”,而是:
能不能安全地用?能不能低成本地用?能不能快速部署?能不能在国产算力体系下稳定运行?
这正是科华数据这篇文章最值得关注的地方。
它不是简单说“科华数据有数据中心”或者“科华数据有液冷”,而是把科华数据放进了一个更大的新框架里:
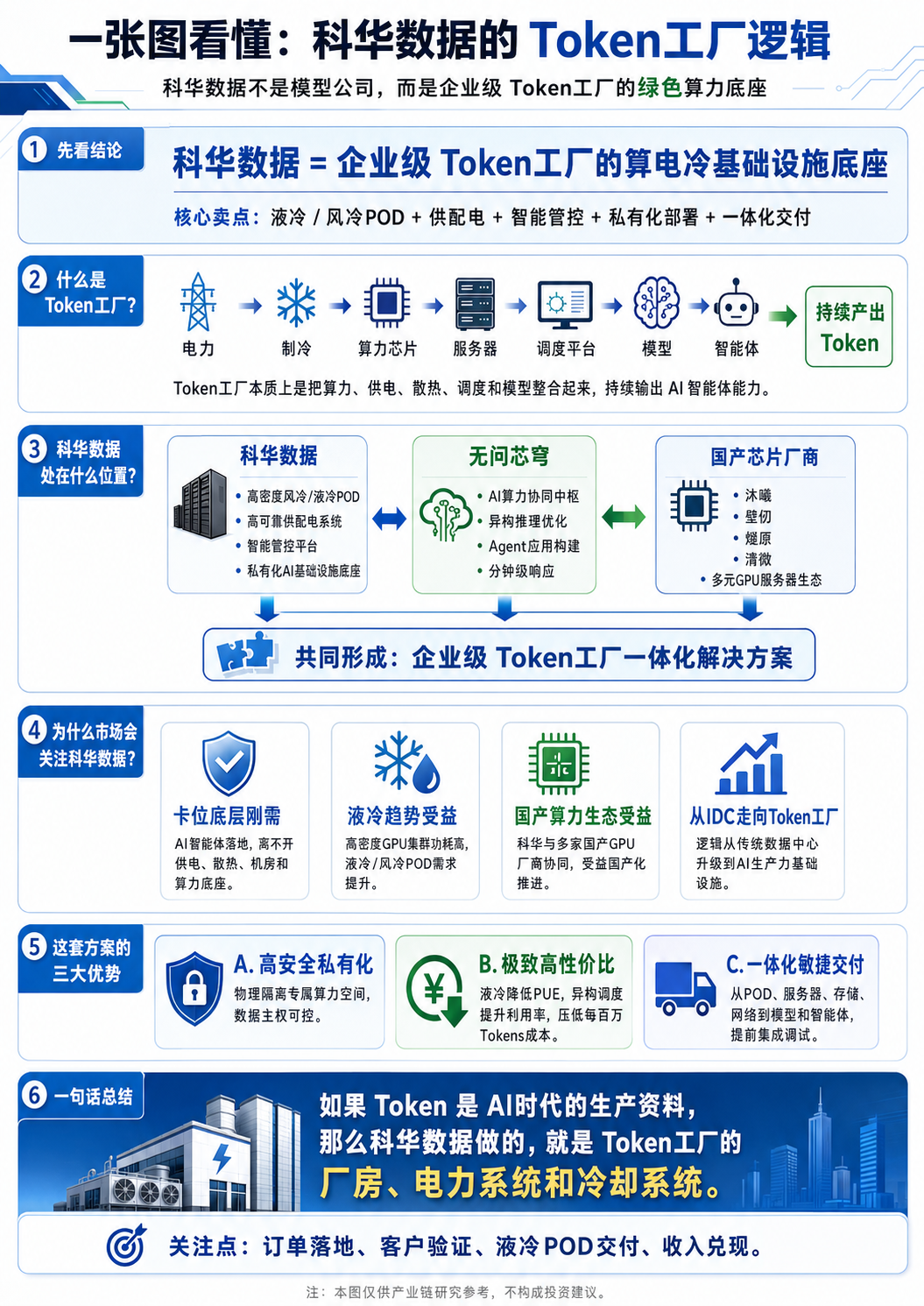
企业级 Token 工厂一体化解决方案。
一、什么是企业级 Token 工厂?
过去我们理解 AI 算力,更多是看:
服务器、GPU、机房、电力、液冷、网络。
但到了智能体时代,企业最终需要的不是单纯买一堆服务器,而是要稳定地产生 AI 生产力。
这个生产力可以用一个更直观的指标来理解:
Token。
大模型回答问题、生成代码、生成报告、驱动智能体执行任务,本质上都在消耗和生产 Token。
所以所谓 Token 工厂,可以理解为:
把算力、电力、液冷、国产 GPU、模型调度、智能体平台整合起来,形成可以持续稳定生产 Token 的企业级 AI 基础设施。
简单说:
传统数据中心 = 放服务器、供电、制冷、联网
Token工厂 = 让服务器真正跑起来,持续输出AI智能体能力
这就是科华数据这次逻辑升级的关键。
二、科华数据在 Token 工厂里处于什么位置?
科华数据不是模型公司,也不是 GPU 芯片公司。
它在这套方案里的定位非常清楚:
绿色算力底座提供方。
具体来说,科华数据承担的是企业级 Token 工厂最底层、最基础、也最关键的物理设施部分:
高密度风冷 / 液冷算力 POD
高可靠供配电系统
数据中心基础设施
智能管控平台
国产 GPU 集群运行环境
企业私有化部署的物理载体
这意味着科华数据不是在讲一个普通 IDC 故事,而是在把原来的数据中心能力升级成:
AI智能体时代的算电冷一体化底座。
三、这套方案为什么重要?
文章里有一个很核心的组合:
科华数据 + 无问芯穹 + 国产GPU芯片厂商
分别对应三个环节:
角色负责什么产业链位置科华数据风冷/液冷POD、供配电、数据中心底座算力基础设施国产芯片厂商沐曦、壁仞、燧原、清微等GPU算力国产算力核心无问芯穹异构算力调度、推理优化、Agent平台软件协同中枢
这套组合的本质是:
用国产 GPU 做算力引擎,用无问芯穹做调度大脑,用科华数据做物理底座,共同构建企业级 Token 工厂。
它解决的是企业落地 AI 智能体时最现实的几个问题:
数据不想上公有云
担心大模型幻觉和安全问题
国产 GPU 异构环境复杂
算力集群散热和能耗压力大
企业没有能力自己搭建完整 AI 基础设施
智能体部署周期长、运维门槛高
所以这套方案不是单点产品,而是一个完整闭环:
芯片 → 服务器 → 风/液冷POD → 供配电 → 调度平台 → 模型 → 智能体 → Token产出
四、科华数据的核心看点:从“卖设备”到“卖AI基础设施能力”
科华数据过去最强的标签是:
UPS
电力电子
数据中心
高可靠供配电
液冷
智算中心基础设施
这些能力原来更多服务于传统数据中心和云计算。
但 Token 工厂时代,逻辑发生了变化。
企业要部署智能体,底层必须有高密度算力。高密度算力必然带来:
功耗上升
散热压力上升
供电复杂度提升
运维难度提升
PUE要求更高
算力稳定性要求更高
这正好对应科华数据的能力圈。
所以科华数据这次最重要的变化是:
它不只是给数据中心供电、制冷,而是成为国产 AI Token 工厂的底层基础设施集成商。
这比单纯讲“液冷概念”更进一步。
五、三大优势:安全、成本、交付
文章里总结了三大核心优势,这三个点其实正好对应企业客户最关心的问题。
1. 高安全私有化
企业最怕什么?
数据泄露。
尤其是金融、政务、能源、制造这些行业,不可能把所有核心数据都随便丢到公有云大模型里。
科华数据的高密度风冷 / 液冷 POD,加上供配电系统和智能管控平台,可以为企业提供相对独立的专属算力空间。
这对应的是:
企业私有化 AI 基础设施。
也就是说,企业可以在自己的可控环境里部署智能体,数据不出域,算力可控,安全边界更清楚。
2. 极致高性价比
企业部署 AI 最怕的第二件事,是成本失控。
大模型不是一次性买断,而是长期消耗 Token。
智能体越多、任务越复杂、调用越频繁,Token 消耗就越大。
这时候,成本控制就变成核心竞争力。
科华数据的价值在于:
液冷降低能耗
高密度POD提升算力部署效率
国产 GPU 降低算力采购成本
无问芯穹提升异构算力利用率
调度优化降低每百万 Token 成本
所以这套方案真正想讲的是:
让企业用更低成本持续生产高质量 Token。
这就是“Token 工厂”区别于普通智算中心的地方。
3. 一体化敏捷交付
企业自己搭建 AI 智能体底座,难度很高。
要买服务器、选 GPU、做液冷、配电、组网、部署模型、调度算力、搭建 Agent 平台,还要做安全、运维、扩容。
任何一个环节卡住,项目就落不了地。
而这套方案强调的是:
从风/液冷POD、多元GPU服务器集群、存储、网络、调度平台、模型、智能体,提前完成集成调试。
换句话说,它不是卖零件,而是卖一套可以快速部署的企业级 AI 基础设施方案。
这对企业客户非常重要。
因为企业买的不是“技术概念”,而是:
能不能尽快用起来。
六、科华数据在 Token 工厂产业链中的位置
可以这样给科华数据定位:
科华数据 = 企业级Token工厂的算电冷基础设施底座
如果把 Token 工厂拆成产业链,科华数据处在这里:
环节代表内容科华数据位置算力芯片沐曦、壁仞、燧原、清微等国产GPU合作生态服务器集群多元GPU服务器一体化集成配套供配电UPS、配电、能源管理核心优势散热风冷、液冷、POD核心优势调度平台无问芯穹异构推理优化合作生态模型与Agent企业智能体应用方案上层Token产出企业级AI生产力最终目标
所以,科华数据不是 Token 工厂里最上层的应用公司,而是最底层的基础设施公司。
但正因为它在底层,反而决定了整个系统能不能稳定运行、能不能降本、能不能规模化交付。
它不是模型方,不是芯片方,而是企业级 Token 工厂的绿色算力底座。
如果说 Token 是 AI 时代的新生产资料,那么科华数据要做的,就是为企业搭建能够持续生产 Token 的“厂房、电力系统和冷却系统”。
这就是科华数据 Token 工厂逻辑的核心。
最后老师们点赞留言转发,并祝老师们一路长虹~~~
作者声明: 本文转载自第三方,旨在提供资讯参考,并非证券推荐或投资建议。作者对内容的真实性、准确性不承担保证责任。本文不构成任何投资建议或证券推荐。截至发文日,作者与文中提及的标的不存在持仓关系。