个人牛市感悟:科技每次大调整都是上车绝好机会
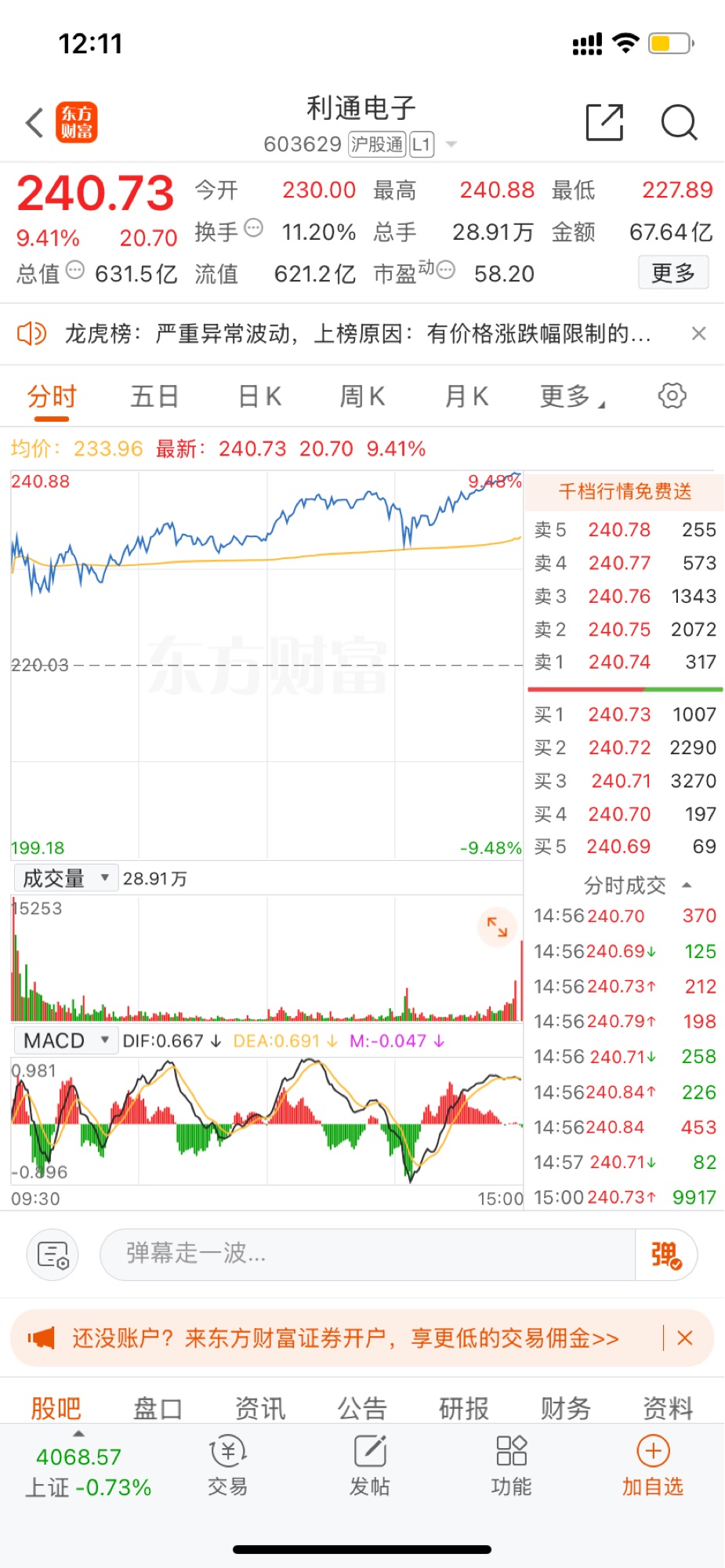
周五太多人疯抢,导致利通严重异动了!
这票如没有异动,估计还会继续涨(个人觉得)
还会有新高
看行业现实
国产算力vs英伟达 区别在哪?
1、堆卡就能赢英伟达?国产算力现实太残酷!别被低价骗了,国产卡堆数量也难平H100,行业真相:国产算力靠堆数量抗衡英伟达,根本是伪命题。
2026年实测,H100单卡月租5.5-5.8万。训练性能是寒武纪MLU590的2.3倍,昇腾910的2.5倍。千卡训练集群,H100凭NVLink互联,算力利用率95%。国产卡堆2倍数量,利用率仅70%,
训练周期多30天。价格更经不起算。昇腾910年租24-26万。单卡性能仅H10040%,想达到H100同等算力,国产卡需堆2.5倍,年总成本反超10%,还不算额外运维成本。新机房疯狂加国产算力,但高端训练仍缺生态。国产卡适合推理与中小模型,核心训练还得H100。
2、算力软硬件加工程化协同是关键。
实际去问了一些做数据中心生意的行业内的朋友,已经建好的以及正在建的真正用国产算力卡的连10%都不到,别说计算只说推理,跑推理用的最多的、性价比最高的还是英伟达,甚至一些中小型的数据中心主力卡用的都是英伟达的5090。
是的,你没听错,5090一张消费级显卡成了今天中国推理数据中心的主力卡之一。
那不是说寒王、沐曦这些公司的卡已经追上英伟达的H200了吗?怎么装机量连10%都不到?这跟国产算力崛起的叙事、差了一个时代,这很反常识对吧?
为什么要理解这件事?得先讲清楚国产芯片本身真的不行吗?其实也不是中国最强的那几家,海光DCU、华为、寒武纪、燧原等等,单卡参数早就追上了H20了,某些规格甚至超过了。
为什么企业还是不用?我给你算笔账你就明白了。假设一家中型企业要部署AI推理能力,需要采购100张的高端卡。如果选择英伟达,卡贵,单价是国产的1.5到2倍,但买回来开箱即用,2到3周就能上线,兼容所有的主流模型,所有的主流框架,出问题有全球的技术支持,CUDA社区啥问题都有解决方案,运维团队5个人就够了。
但是选国产,它虽然卡便宜,但买回来之后解决的问题有一大堆,然后模型适配,你要跑哪个?开源模型可能根本没在国产芯片上适配过,要么自己花几个月做适配,要么干脆跑不动。其次就是性能打折,就算跑通了,实际性能往往只有标的60%到70%。
还有就是生态的割裂,就比如a厂的卡跑通了,b厂的卡又得重新搞一遍。然后就是运维的扩编,要专门养一只适配的团队,最少也得10个人起步,出问题还没人管,技术支持的效率不如英伟达。
所以这笔账算下来,国产芯片单卡虽然便宜30%到40%,但加上隐性成本,总账比英伟达贵太多太多了,而且更要命的就是慢。对于一家企业来说,AI业务每晚上线一个月,竞争对手就多跑出去一大截,时间成本比硬件成本要贵100倍。
所以国产算力的落地难根本不是芯片不行,是整条链路还没有打通。我把这条链路上的痛点拆开给你看。
· 第一个痛点:硬件买回来跑不起来。国内做AI芯片的公司一大堆,每家架构都不一样,模型迁移到国产平台常常要面临功能缺失、精度损失、性能骤降的困境。不是芯片设计有问题,是配套软件栈成熟度参差不齐。
· 第二个痛点:产业链全是孤岛。芯片厂只管单卡的参数,整机厂只管硬件集成软件框架,只管自己的工具好不好用,应用厂只管业务能不能上线。没有人对整条链条上的最终效率负责,每一层都很努力,但最终用户疲于在不同的技术路线之间整合资源,严重内耗。
· 第三个痛点就是高端集群搭不起来,跑万亿参数大模型必须要靠万卡级的集群。但国产芯片大规模组网有几个老大难问题,互联协议各家不同,通信的带宽不够,散热和电力工程化的能力不足,结果就是单卡能跑,集群搭不起来,大规模训练只能依赖英伟达。
所以这三个痛点叠加在一起就是今天国产算力的真实困境,不是没卡,是有卡用不好,不是不能用,是用起来太贵太慢。所以企业老板算账之后还是去买英伟达5090、H20,
这就是说为什么国产替代真的有很长的一段路要走。
作者声明: 本文转载自第三方,旨在提供资讯参考,并非证券推荐或投资建议。作者对内容的真实性、准确性不承担保证责任。本文不构成任何投资建议或证券推荐。截至发文日,作者与文中提及的标的不存在持仓关系。