1. 定制XPU(ASIC) :为AWS、微软、谷歌等云巨头定制AI加速芯片,与英伟达GPU形成互补。
2. 光通信DSP:高速光模块中的核心芯片,负责信号的高速调制解调,是光互联的“大脑”。
3. 高速SerDes:芯片内部及芯片之间的高速数据传输接口技术,是连接性的底层基础。
4. 硅光子与CPO技术:通过收购Celestial AI等布局,掌握将光信号直接送入芯片封装内部的“光子织网”技术。
5. 以太网交换机芯片:新发布的100T以太网交换机,具备行业最低功耗,专为AI数据中心设计。
2026年3月,英伟达宣布向Marvell战略投资20亿美元,是英伟达继Lumentum、Coherent后最大的一笔产业链投资,也标志着双方“联姻”合作正式开启,Marvell从“供应商”升级为“生态核心伙伴”。
对于这次事件,最关键的不是Marvell的想象力,而是黄仁勋话语背后的深层逻辑:AI基础设施的瓶颈正在从“算力”向“连接”转移。
第一阶段:算力瓶颈。
2023-2025年,AI大模型训练需求爆发,英伟达GPU凭借CUDA生态+高带宽优势垄断高端算力市场,2026年市值突破5万亿美元,成为全球首家达此里程碑的科技公司。但单一芯片算力提升已遭遇物理瓶颈:单芯片功耗突破1000W,单卡算力增速从每年2倍降至1.3倍,“算力墙”显现。
第二阶段:内存瓶颈。
2025-2026年,随着万亿参数模型训练需求爆发,HBM成为新瓶颈:单H100需80GB HBM3,Blackwell需192GB HBM3E,内存成本占GPU成本40%+。三星、SK海力士、美光凭借HBM技术优势,先后在2026年市值突破1万亿美元,内存成为AI第二增长极。
第三阶段:连接瓶颈(正在发生)。
当算力和内存都大幅提升后,如何将数百万颗处理器高效协同、让数据以极低延迟和功耗在芯片间、机柜间传输,成为限制系统性能的最后一公里。当前AI集群的瓶颈已从“算力和内存不足”转向“连接不够快、不够宽”。
据伯恩斯坦测算,2025年AI连接市场规模140亿美元,2030年将达730亿美元,年复合增速39%,占AI基础设施总市场的39%,是AI产业链增长最快的环节。Marvell作为该领域市占率超30%的龙头,直接受益这一浪潮,这也是黄仁勋给出“万亿美元市值”预判的核心依据。
黄仁勋也再次强调,AI正在迈向智能体模式——一个复杂任务被拆解成无数子任务,分布式部署在巨大的计算集群中并行处理。这种模式对集群内和集群间的通信带宽与延迟提出了极高要求。连接的优劣,直接决定了Token的生产效率和成本。
万亿连接市场的核心环节:
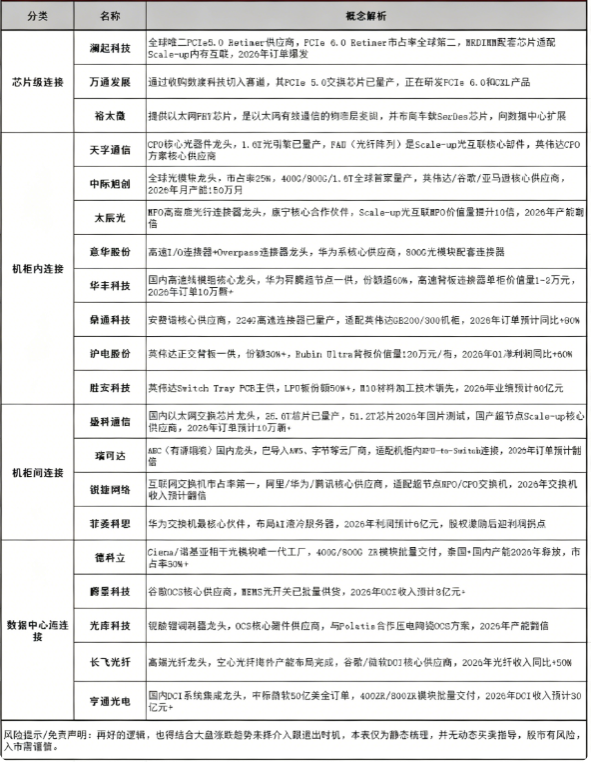
1. 芯片级连接(XPU-to-XPU,Scale-up核心)。在芯片内部,计算核心之间的互联效率决定了单芯片的性能上限。主要包含高速SerDes、Scale-up交换芯片、CXL交换芯片等环节。
2.
机柜内连接(Rack-scale)。英伟达的定调是“能用铜缆的地方就用铜缆,必须用光学器件的地方才用光学器件”,目前铜背板仍是主流,但“铜墙”正在逼近。当速率达到224G甚至448G per lane时,机柜内部也将大面积“光进铜退”,CPO技术应运而生——将光引擎直接与交换芯片封装在一起,彻底消除信号在PCB上传输的损耗和距离限制。
3.
机柜间连接(Scale-out)。成千上万个机柜通过以太网交换机互联,形成万卡甚至十万卡集群,这一层目前主要依赖可插拔光模块,其中DSP(数字信号处理器)芯片正是光模块的核心,也是Marvell的拳头产品。
4.
数据中心间连接(DCI)。随着电力供应和土地资源的限制,单一数据中心不可能无限扩大,未来将走向多地分布式训练与推理。连接不同地理位置的智算中心,需要相干光通信技术,实现数百公里以上的超高速、大容量数据传输。
作者声明: 本文转载自第三方,旨在提供资讯参考,并非证券推荐或投资建议。作者对内容的真实性、准确性不承担保证责任。本文不构成任何投资建议或证券推荐。截至发文日,作者与文中提及的标的不存在持仓关系。