事件:智谱率先在 GLM-5.1 线上生产集群中完成了新一代组网架构 ZCube 的规模化落地。(ZCube是智谱、驭驯网络与清华大学在网络领域会议ACM SIGCOMM2025上发表的网络架构)
这是该技术首次大规模运用于生产推理集群中,智谱联合驭驯网络与负责网络架构升级和优化工作,组网架构优化基于锐捷网络交换机。


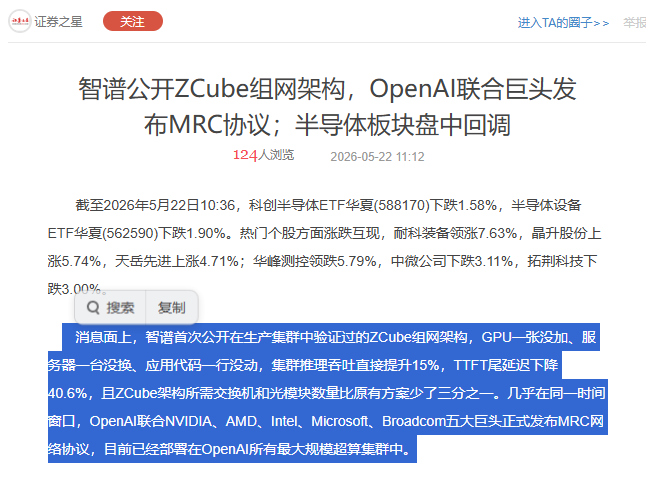
效果:新一代组网架构下,在不新增任何 GPU、不修改任何应用代码的前提下,集群推理吞吐提升了 15%(不加一块GPU,算力瞬间多出15%),首 Token 响应的尾延迟(TTFT P99)下降了 40.6%,交换机与光模块硬件成本减少了三分之一。或许,在扩大 GPU 规模之外:网络,已经成为超大规模 AI 基础设施的下一个主战场。

几乎在同一时期,OpenAI联合NVIDIA、AMD、Intel、Microsoft、Broadcom等五大巨头发布了MRC协议,并已部署于其最大规模超算集群。两大领先模型厂商同时动作,共同印证了网络已成为超大规模AI基础设施竞争的新战场。
在 GPU 价格高企、算力供给偏紧的大环境下,多数公司的注意力仍然集中在「如何获得更多 GPU」上。但 ZCube 用真实的生产数据证明,在 GPU 资源不变的前提下,纯粹通过网络架构升级就能释放 15% 的额外算力,同时节省三分之一的网络成本。如果将这一比例外推到万卡甚至十万卡规模,网络优化所释放的价值将远超一般认知。
AI 算力竞赛的下半场,胜负可能取决于那张「看不见的网」。
作者声明: 本文转载自第三方,旨在提供资讯参考,并非证券推荐或投资建议。作者对内容的真实性、准确性不承担保证责任。本文不构成任何投资建议或证券推荐。截至发文日,作者与文中提及的标的不存在持仓关系。